
Perudo Blog
I've known of this game since 2019. We used to play with cards instead of dice, which ended up removing much from the complexity of the game. Now, you can play with friends at perudoonline.com without owning a truly questionable number of dice.
A little about the game -- it's a survival game where you win by being the last player standing. Here are the rules if you want to learn more; they're also available on the website. See if you can come up with a strategy to beat your friends!
AI
(07-18-25) With some clever tricks, I've found a nash equilibria for the 2 die vs 2 die game! The 2v2 player one payoff is -0.0168. In the 2v1 game, the player one payoff is 0.2748. In the 1v2 game, the payoff is -0.2716. The latter two results agree with other online computations, but I am the only one to have ever solved the 2v2 game!
I've stumbled upon some interesting facts about nash equilibria. I intend on rearranging this exposition (including my 06-05-25 post) within this page, but for now it remains here. There are two principled types of equilibria that are improvements on the naive nash equilbria in sequential games: normal-form perfect equilibria and sequential equilibria. These both have nice properties. There is an algorithm that actually finds an equilibria fitting both these descriptions. I tried to implement it, but doing so would require use of a symbolic solver (Google OR-tools will not suffice.) Instead, I've settled for a NE that shares certain proprties with Sequential Equilibria.
Anyways, enjoy a striking representation of an optimal P1 first-move strategy! On the first turn, only one-of-a-kind claims are called. Unlike the 1v1 case, strategies with deterministic first-move profiles are no longer capable of achieving the optimal value (that is, there is no equilibrium that produces 36 monochrome pie charts.)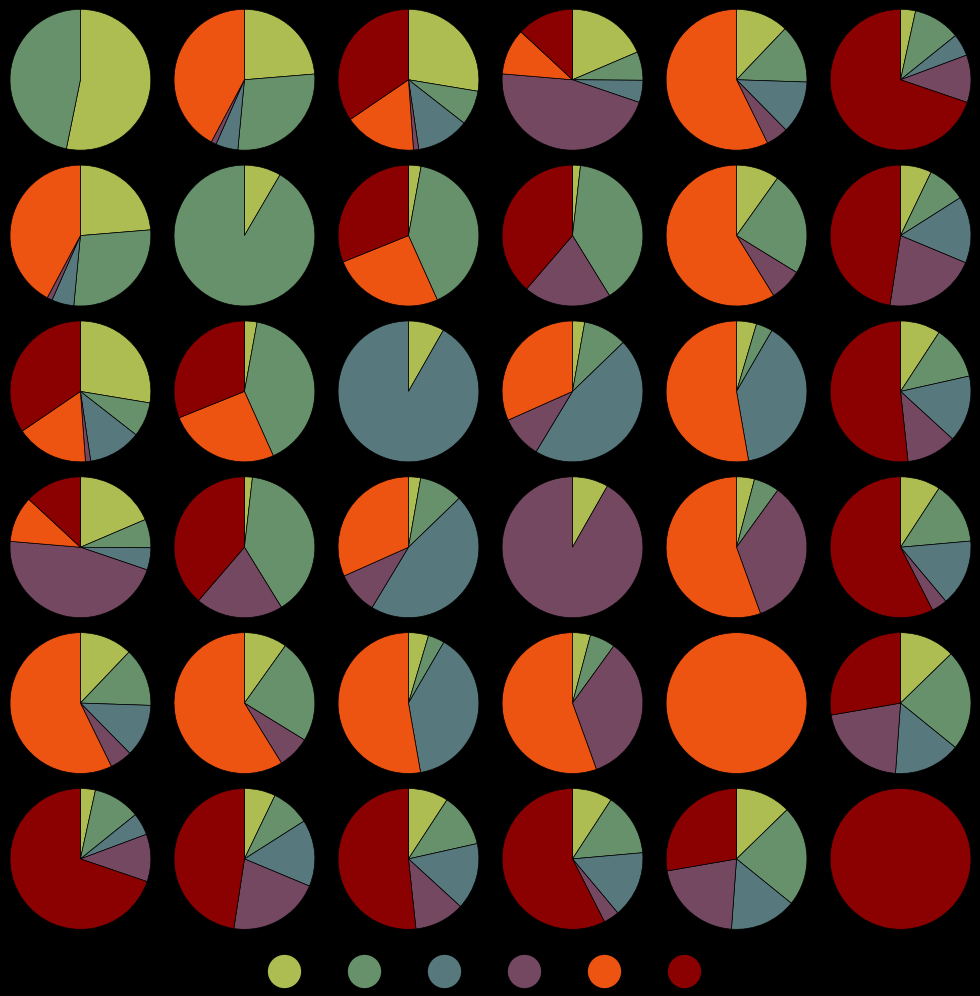
(06-05-25) Heads up, one die each. You roll a 4. Your opponent calls 2 3s. What is your best response?
Obviously, you should call BS. But there exists a nash equilibrium where you simply resign. I nodelocked my solver (some of it is on Github) to call BS, and the minimax payoff did not change -- which means that calling BS instead of resigning is also a nash equilibrium.
Why? To put it concisely, resigning is only weakly dominated by calling BS. And weakly dominated strategies may be a part of a nash equilibrium (NE). In this particular case -- if our opponent tries to exploit our resign, they will lose too much EV by calling 2 3s when we don't have a 4. So our opponent can't exploit our resign. The solver is very good at working in bad moves and working around them. The set of NE is not only trivially infinite, but also difficult to describe in its entirety. There are many situations where we can make clearly bad moves at cetain nodes of the game tree, and our opponent can't efficiently exploit them because they don't know what die we have. (If you've nodelocked with GTOWizard -- this is the same reason why GTOWizard will give you weird looking strategies at not-often-traversed-nodes of the game tree.) I've included the first move distribution for a particular equilibria: bluff iff you rolled a 1 or a 2.
(05-30-25) Perudo is just large enough to put naive LP-solving out of reach, as I found when I coded up a naive solution -- represent your strategy as a mix of all pure strategies, then iterate over opposing strategies and find a distribution that does well vs all of them. There are on the order of 12^(2^11) opposing pure strategies. Solution: use the Koller-Megiddo-Strengel algorithm that works with sequential representations of games.
I have to make optimization choices, because the Koller algorithm as implemented on PyGambit doesn't exploit properties of Perudo and results in something like 12 hours of computation to solve the 1v1 game. So I reimplemented the algorithm, adding simple optimizations like: when a matrix is guaranteed to be sparse, represent it as such. We've gotten to a 20000x speedup, and now we can solve the 1v1 game in 2-3 seconds.
(01-13-25) My overall goal is to beat dudo.ai. The core idea is fine-tuning counter-factual regret techniques using pytorch, which is similar to experts. Thus far, I've ported some code to a collab notebook for CUDA (GPU) access, coded up a lot of utilities, and trained 2 models for a (measly) 6k iterations, varying a hyperparameter that I invented. As expected, one model simplifies strategies a little more aggressively than the other.
I've experimented with regret-hedge algorithms, including the one at https://arxiv.org/pdf/0903.2851 that tried to avoid the problem of tuning a learning rate parameter. However, when I implemented it, weighting weights in proportion to re^(r^2) empirically just converges poorly because the strategy "likes leaf nodes too much"
